3-7: Dyna
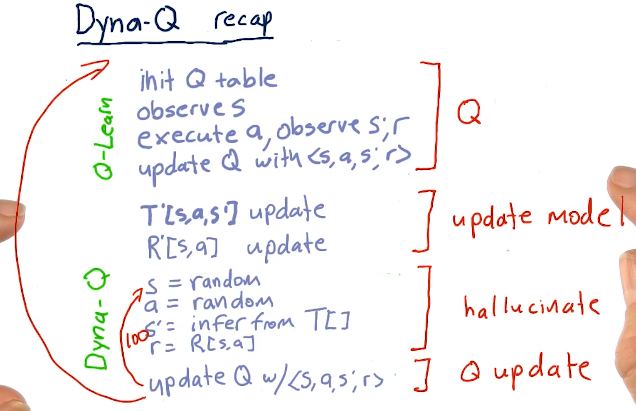
The issue with Q-learning is you have to execute real trades to receive feedback from the real world in order to converge while learning. Rich Sutton invented Dyna to solve this problem. Dyna builds models of T, the transition matrix, and R, the reward matrix, and then, after each interaction with the real world, hallucinates many additions interactions - usually a few hundred.
Dyna-Q big picture
With Dyna-Q, we have a Q table that is influenced by real-world actions, states, and rewards. After this expensive operation is done, we take those findings and update our backend Dyna-Q T and R models. We conduct an iteration 100 times, learning about the information we just received from the real world and this is used to update our Q-learner used for real-world solutions.

Learning T
We start of with T being equal to 0.00001. While executing, if we observe a state of S transitioning to S prime due to some action, we increment the counter for that respecting T location.

Evaluating T
We evaluate T by determining the probability we'll end up here based upon taking this action and arriving at this state, using historical data. Essentially, we'll take Tc, number of times we've been at this state due to action at S, and we'll divide that by the sum of the number of times we've been at this state and have taken the same action and arrived at a different or the same state. This essentially just iterates through all states related to this action.
This gives us the probability of arriving at state S prime. Equation from the lecture is provided below:

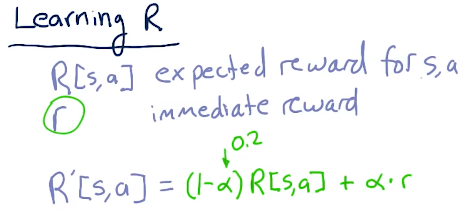
Learning R
R is the expected reward for a state and action and r is the immediate reward we experienced for this state and action. R prime is the update we make for this R after receiving new observations, and it's similar to updating Q. Below is the equation for this:
Recap
Below is a high-level recap from the lectures: