3-5: Reinforcement learning
Reinforcement learners provide policies on which actions to take. Recently we've only been focused on regression tree learners.
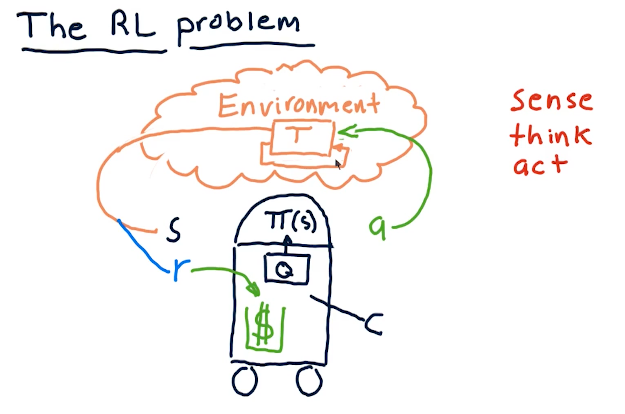
The RL problem
The professor breaks down reinforcement learning in the terms of robotics, since he's originally a roboticist. These concepts can also be applied to stock trading, but the pieces of the puzzle are as follows:
- reinforcement learning follows a sense, think, act cycle.
- We have some policy called pi that receives the state of the
environment, S.
- pi generates some action, A.
- This action has some affect on the environment.
- Changes are made to the environment based upon our actions, and then we sense again to acquire the environment's state S.
- Ultimately, we receive some reward R from our actions on the environment, and we want our reinforcement learning to maximize that reward.
- Finally, our algorithm Q interprets what actions generate a state that ends up in a reward, and uses this to update the pi policy.
All of these concepts can also be applied to a Q-learning robot that generates orders in the stock market. Please find below a high-level overview from the course:
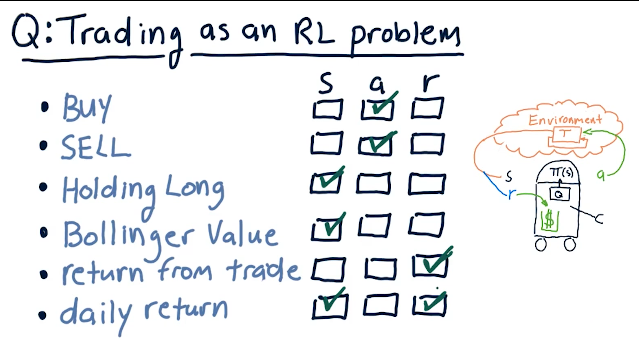
Trading as an RL problem
The professor provides us with a quiz to break down different actions, states, and rewards in regards to trading:
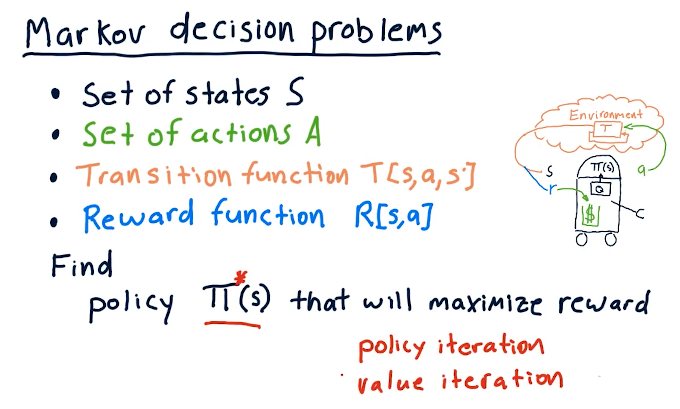
Markov decision problems
Pretty much covers the previous sections, however, we discuss transition functions where we identify states S, some action A, and then we find probabilities to end up in state S prime. Our transition function must sum all probabilities for this three-dimensional data structure to 1.0. We also have a reward function that identifies that some state S also provides us with a reward by executing action A.
So the purpose of solving this problem is to find policies pi that interpret S to maximize reward. How we do this is via:
- policy iteration
- value iteration
Unknown transitions and rewards
Experience tuples are sets of data that relate a state, an action, a state prime after the action occurs, and a reward. As we continue to encounter new situations, this data structure increases in size with the number of experiences.
We can leverage this data in two ways to conduct reinforcement learning:
- model-based
- build a model using transition functions and reward functions
- conduct value or policy iteration
- model-free
- this involves q-learning where we inspect the data as a whole
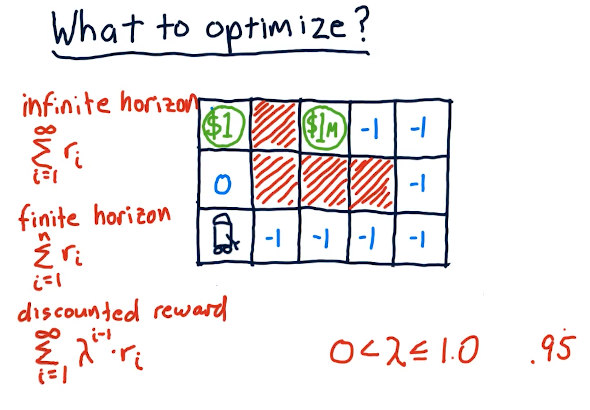
What to optimize?
The professor discusses the different types of reward given the amount of time we have to acquire that reward - our horizon. In the slide below, the robot searches for a reward - obviously the $1 reward is more immediate while the $1M reward is harder to reach.
What we use in Q-learning is the discounted reward, modified by gamma as the horizon approaches infinity. Gamma can effectively be our interest rate and, as we see here, it effectively devalues our reward as time goes on. This is all to say that money today is worth more than money tomorrow.